
原文标题:MINER: A Hybrid Data-Driven Approach for REST API Fuzzing
原文作者:Chenyang Lyu;Jiacheng Xu;Shouling Ji;Xuhong Zhang;Qinying Wang;Binbin Zhao;Gaoning Pan;Wei Cao;Peng Chen;Raheem Beyah
第一作者主页:https://lyuchenyang.github.io/
发表期刊:32nd USENIX Security Symposium
主题类型:漏洞检测
笔记作者:宋霁洋@Web攻击检测与追踪
MINER的基本框架如下图所示,主要由5部分组成:序列模板选择模块、生成模块、Fuzz模块、收集模块、注意力模块。
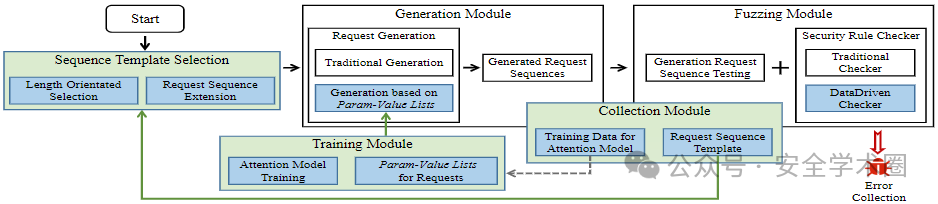
基本的工作流程就是MINER持续生成连续的请求来测试云服务的rest api。MINER如同已经存在的fuzzer一样在编译模块构建请求模板来测试rest api。首先,利用序列模板选择模块,在概率上根据长度选择请求序列模板,然后延展这个序列。再用生成模块生成序列模板中的模板请求并构造能够使用的序列。模糊测试模块会测试生成的请求序列。收集模块会收集历史数据。历史数据应是有效请求并且相关变异的参数。用参数值对,来表示变异参数以及在请求生成中使用的值。最后,周期的在训练模块用收集到的键值对来训练一个注意力模型。用这个训练的模型,对每一个请求模板来生成需要的键值对。
序列模板选择模块
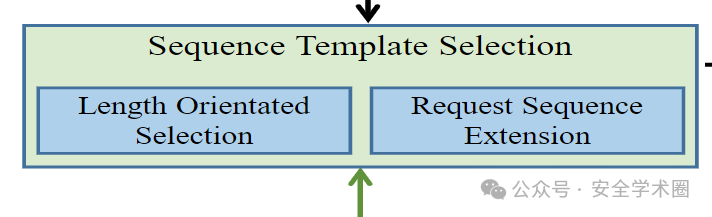
在这个组件中,MINER 基于从收集模块收集的种子序列模板构建候选序列模板。具体来说,MINER 首先根据其长度为每个种子序列模板分配不同的选择概率。序列模板越长,其选择概率越大。其次,对于每个选定的序列模板,MINER 执行扩展过程以构建候选序列模板。换句话说,MINER 在所选模板的末尾添加了一个新的请求模板。基于上述设计,MINER 实现了长度定向序列构建。
生成模块
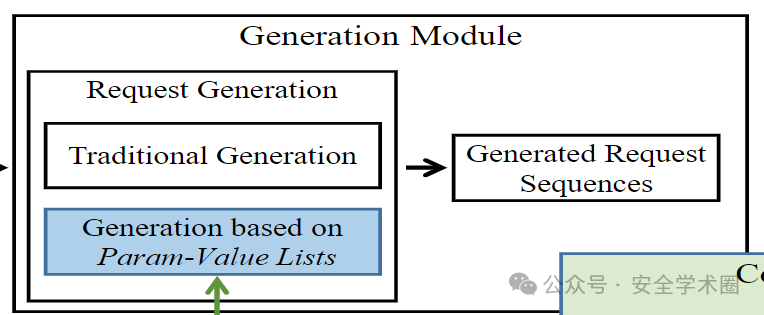
在这个部分中,MINER会在候选序列模板中生成每个请求,即MINER会为每个参数分配一个值,不包括请求中的目标对象 id。如图3所示,MINER实现了两种方法来生成请求。第一个是传统的生成方法,即为每个参数随机选择一个替代值,第二种方法的过程如下所示。
为了生成请求,MINER 1) 为每个参数选择默认值;2) 找到那个用于变异的键值对的集合,这个集合是通过注意力模型对这个模板生成的;3) 根据均匀分布从键值对集合中概率的选择候选概率键值对;4) 根据键值对集合中选定的值,来调整参数。对于不在所选参数值列表中的参数,MINER 保留在请求生成中使用的默认值。通过执行上述过程,MINER 实现了基于注意力的请求生成。
在实现中,为了生成包含 n个请求的序列,MINER 使用键值对表的方法来生成前 n-1 个请求,并使用传统的生成方法生成最后一个请求。原因如下,在生成前 n-1 个请求时,MINER 希望利用键值对表来提高生成质量。这有助于触发目标云服务的正常执行。然后,MINER 利用传统的生成方法生成最后一个请求,以增加触发异常行为的概率。
Fuzz模块
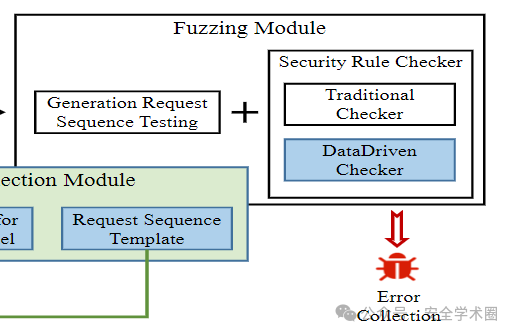
在这个组件中,MINER执行以下过程来探索独特的错误。首先,MINER通过其REST API将生成的请求序列发送到云服务,并分析每个请求对应的响应。如果MINER收到了一个50×范围内的响应,MINER认为对应的请求触发了错误,并将生成的序列及其响应存储在本地以供将来分析。其次,MINER利用每个安全规则检查器对当前请求序列进行变异,以触发特定的规则错误。特别是,我们提出了请求参数违规检查,并实现了一个名为DataDriven Checker的新安全规则检查器,以找到由于未定义的参数使用而导致的错误。
一般来说,供应商为每个请求定义特定的参数,以触发云服务的特定行为。如果用户向请求添加未定义的参数并将其发送到云服务,则云服务通常会忽略未定义参数的不正确使用,并根据定义的参数值执行行为。然而,由于各种情况,云服务可能会根据未定义的参数执行意外行为。
为了捕捉这种规则违规,DataDriven Checker 在生成过程中向请求添加了一个未定义的参数值对。具体来说,对于序列中的最后一个请求,MINER 随机选择收集模块中收集的未定义的键值对。然后,MINER 将所选的键值对添加到序列的最后一个请求中。最后,MINER通过其REST API将新构建的请求序列发送到云服务。如果云服务在50×范围内返回响应,MINER认为新请求触发不正确的参数使用错误,并在本地存储序列以进行进一步分析。
收集模块

在模糊测试过程中,MINER首先收集有效的请求序列,其中所有请求都通过Fuzz 模块中云服务的检查。这些序列被用作序列模板选择中的种子序列模板,以指导序列构建。其次,MINER分析来自云服务的每个生成的请求的响应,并提取在通过检查的有效请求中使用的键值对。具体来说,如果一个请求在20×和50×范围内收到响应,这意味着请求通过了检查并触发了云服务的某种行为,MINER会分析请求中每个参数的使用值。如果使用的值不是参数的默认值,MINER将该值视为对该参数的关键突变,并将其存储为键值对。因此,MINER为每个有效请求收集了一个键值对列表,其中包含有效的突变,以帮助通过云服务的检查。
贡献分析
贡献点1:论文针对请求序列长度不够,无法发现云服务深层状态问题,提出了面向长度的序列构建方法,实现了面向长度的序列构建,并利用使用过的种子作为种子的模板,来指导序列构建。 贡献点2:论文针对云服务检测通过率低的问题,提出了注意力模型生成键值对方法,实现了一个注意力模型,为关键参数提供合适的值,来提高云服务检查的通过率。 贡献点3:论文针对未定义参数造成云服务错误问题,提出了键值对模糊测试方法,实现了一个能够生成未定义参数的工具,进行安全检查。
代码分析
代码链接:https://github.com/puppet-meteor/MINER
简要对其论文的代码进行点评,点评内容如下:
代码使用类库分析,是否全为开源类库的集成?
MINER 的代码开发是基于RESTler的基础上进行实现的。然而,RESTler[1]工具并没有完全开源。其中在读取swagger规范文件生成相应进行fuzz的api格式中,并没有开源。
代码实现难度及工作量评估
代码实现的相关功能模块并不是过于复杂,但是工作量偏多。因为是在RESTler的基础上,用相关的python代码实现自己的各个创新点模块。
代码关键实现的功能(模块)
代码主要实现的有注意力模型生成的模块、面向长度的序列构建模块。还有未定义参数检测模块。
论文点评
MINER不同于APIfuzzer[2]与TnT-Fuzzer[3]两者。因为,大部分对REST API的模糊测试对连续的请求序列构建是不足的,如TnT-Fuzzer,只会在单一API的请求参数上进行随机值的变异。这也导致云服务很多深度状态难以达到。MINER的提出确实在这方面有了新的思路,但它依然有局限性。
MINER的局限性以及可能的解决方法如下所示。
数据集的局限:
由于在模糊测试过程中收集的训练数据不足,很难为序列生成训练一个注意力模型。然而,在不同场景下,如连续模糊测试和并行模糊测试,可能会有足够的训练数据用于序列生成。因此,利用机器学习模型为请求序列提供关键的变异策略可能在未来工作中还有待改进。
Bug难以复现的局限:
由于服务器状态的改变,一些唯一的错误只能在云服务的特定状态下触发,而在未来的分析中无法重现。这是REST API模糊测试中常见的问题。例如,一个模糊测试工具可以通过访问一个资源来触发错误,该资源是由其他请求序列几个小时前创建的。然而,在接下来的模糊测试过程中,模糊测试工具删除了这个资源,使错误无法重现。因此,如何分析相距较远的请求序列之间的相关性以及如何重现这种错误可能是REST API模糊测试的一个有趣的研究方向。
参考文献:
[1] V. Atlidakis, P. Godefroid, and M. Polishchuk. RESTler: Stateful REST API Fuzzing. In Proceedings of the 41st International Conference on Software Engineering, pages 748–758, 2019. [2] APIFuzzer: HTTP API Testing Framework. https: //github.com/KissPeter/APIFuzzer. [3] TnT-Fuzzer: OpenAPI Fuzzer Written in Python.https://github.com/Teebytes/TnT-Fuzzer.
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com